Determina el sentimiento
con Data Science
Para el ser humano analizar una emoción o un sentimiento requiere un procesamiento complejo en el cerebro en donde toman un papel importante regiones como el hipocampo, la amígdala y la corteza prefrontal porque es en la corteza prefrontal en donde se analiza la situación en la que ocurre la emoción y podemos entender si esta emoción es apropiada a la situación y cómo respondemos ante ella. Por ejemplo, si yo voy en el tráfico y un amigo me dice que está feliz de hacer dos horas de cola, podría identificar que lo está diciendo con sarcasmo. ¿Será que la tecnología podría interpretar una situación similar utilizando datos que se encuentran en Internet y las Redes Sociales? Aquí te explicaré algunas herramientas de Data Science que existen y que nosotros en Data Lab utilizamos para conocer los sentimientos y emociones de las personas, incluso en difíciles escenarios de sarcasmo.
Algoritmos de análisis de sentimiento
Dentro el campo del procesamiento de lenguaje natural (NLP) existen, actualmente, varios algoritmos que permiten analizar y clasificar sentimiento de forma automática. Te cuento acerca de tres modelos con los que he trabajado:
- K-nearest Neighbors (KNN)
Su nombre en español sería algo como: “Los vecinos más cercanos”. Es un método simple de clasificación que asigna una categoria a un nuevo texto en función de su proximidad o similitud a otros textos en un conjunto de datos. Si la mayoría de textos cercanos son positivos, el nuevo texto también se clasificará como positivo.
Este algoritmo me gusta porque su base matemática, la Distancia Euclidiana, es la que nos da el valor de proximidad de los elementos y es sencilla de comprender. En un espacio bidimensional, la distancia euclidiana entre dos puntos P1 y P2 podría calcularse con la siguiente fórmula (ver imagen)
Por lo general, los textos que tenemos en nuestros datos se representan con más de dos dimensiones, por lo que la fórmula se define como: (ver imagen)

¿Qué hace el algoritmo?
El algoritmo crea un modelo de clasificación que no requiere un proceso de entrenamiento intensivo y es fácil de entender, sin embargo, el mayor reto que hemos tenido al momento de implementar este algoritmo es poder determinar la cantidad adecuada de vecinos (k) con los que se compara el nuevo texto, ya que tomar en cuenta pocos vecinos cercanos afecta la precisión y tomar en cuenta demasiados vecinos afecta el rendimiento del algoritmo. Este algoritmo es útil en pequeños conjuntos de datos y en escenarios donde la simplicidad es clave.
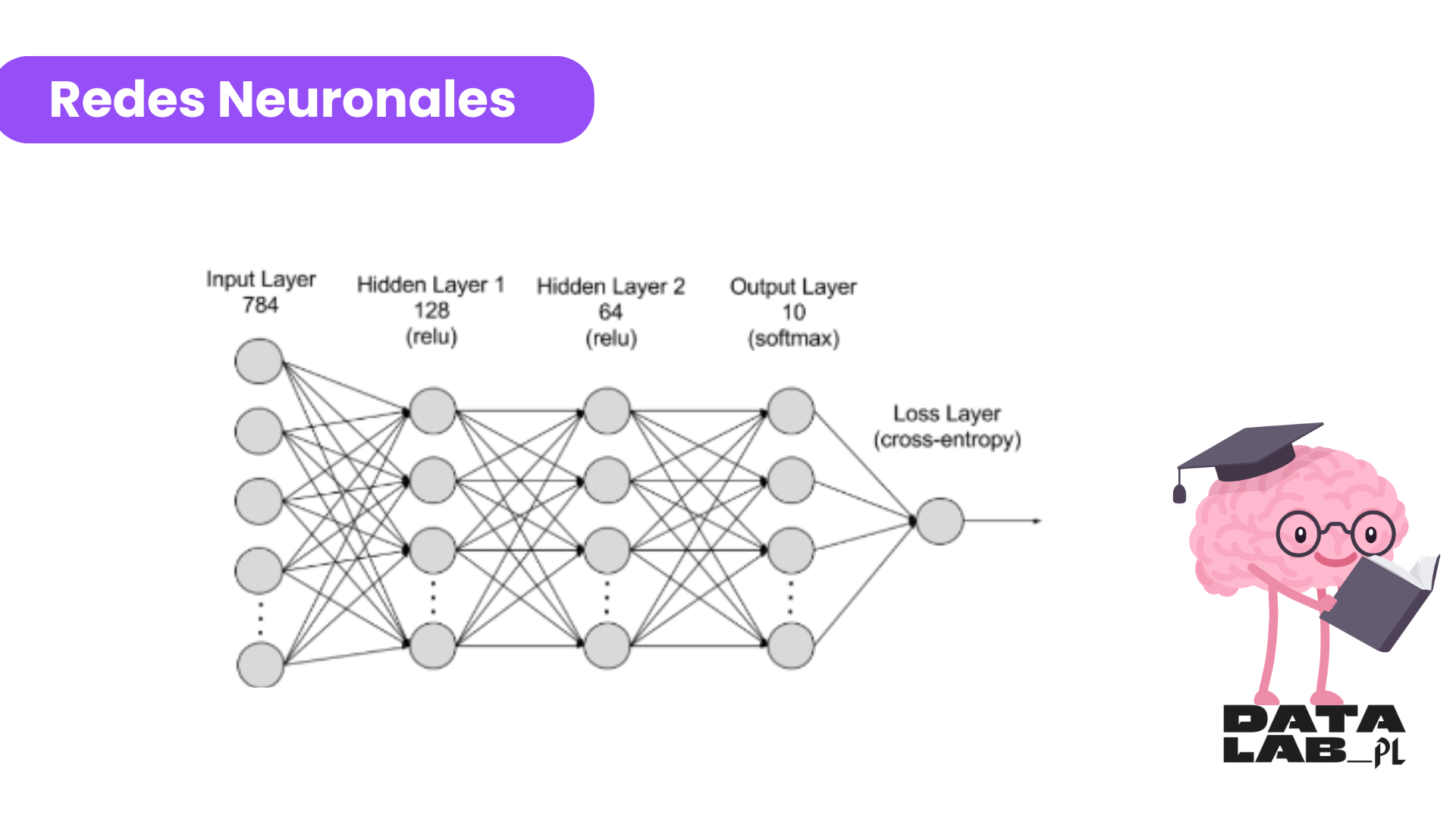
- Redes Neuronales
Las redes neuronales son algoritmos avanzados que han mejorado significativamente el análisis de sentimiento en los últimos años. Los algoritmos de redes neuronales utilizan un conjunto de datos de ejemplo para generar un modelo, en nuestro caso el conjunto de datos de ejemplo son nuestros textos y su asignación de sentimiento realizado por una persona, este conjunto de datos es usado para generar las relaciones entre las variables de entrada y las variables de las salidas del modelo. Como parte del proceso de creación del modelo, una serie de nodos interconectados se van organizando en capas internas entre las variables de entrada y las variables de salida, cada nodo dentro de la red neuronal calcula un valor de salida basado en un conjunto de valores de entrada; el proceso de aprendizaje del algoritmo consiste en generar pesos y conexiones entre los nodos internos de la red neuronal los cuales se van refinando hasta llegar a generar un modelo de predicción de las variables de salida.
Aunque me resulta muy complicado explicar como se calculan los resultados del modelo, estos modelos son muy buenos para trabajar con secuencias de datos como oraciones y textos largos, estos modelos muchas veces se consideran como una caja negra porque es difícil de obtener una explicación útil de como se obtienen los valores de salida. Uno de los mayores retos a los que nos hemos enfrentado al utilizar estos algoritmos es que se requiere una mayor potencia de procesamiento y mucho más tiempo para el entrenamiento del modelo en comparación con algoritmos más simples como “El vecino más cercano”.
Una vez generado el modelo se utiliza para determinar el sentimiento de un nuevo texto. Estos algoritmos permiten que los modelos puedan “entender” mejor el contexto de una oración o párrafo completo, lo cual es esencial para clasificar sentimiento de una manera más precisa, especialmente cuando se tienen textos complejos o ambiguos.
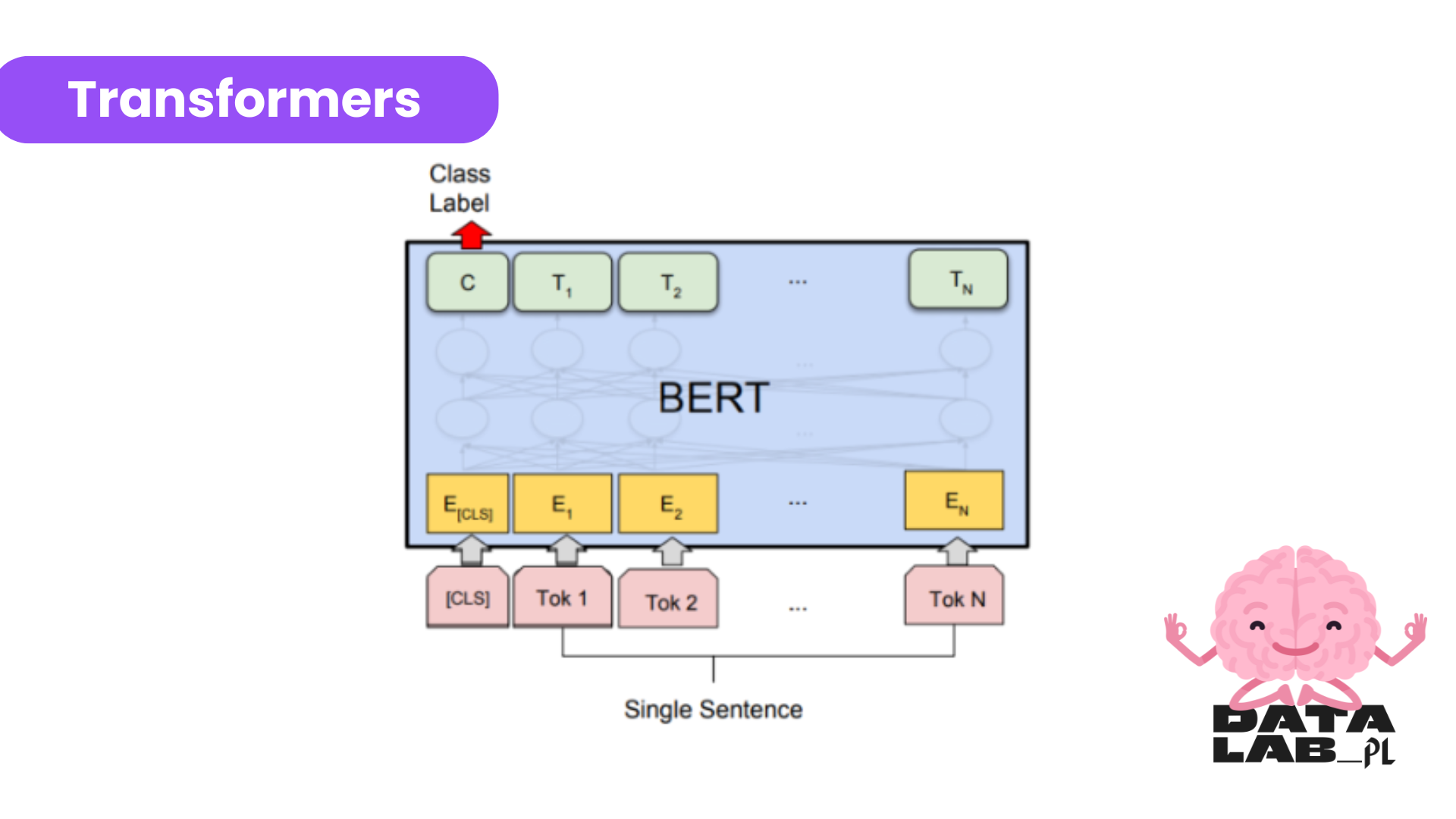
Transformers
Estos modelos han revolucionado el procesamiento del lenguaje natural, estos modelos pueden capturar relaciones contextuales entre palabras en una oración de manera mucho más efectiva. La principal ventaja de estos modelos es la alta precisión en la interpretación del texto y sus capacidades de comprensión contextual superiores a otros algoritmos. Estos modelos requieren una gran capacidad computacional y son mucho más complejos de entrenar, es por eso que solo un grupo limitado de empresas, entre ellas Google, pueden permitirse el lujo de poder entrenar estos modelos desde cero.
Uno de los modelos basado en la arquitectura de Transformadores es BERT (Bidirectional Encoder Representations from Transformers) que fue desarrollado por Google en 2018. Este modelo utiliza una arquitectura neuronal de codificador-decodificador y es bidireccional porque predice las palabras basándose en las palabras anteriores y en las siguientes, durante el proceso de construcción del modelo las palabras se codifican en un token el cual es una representación numérica de cada palabra, además el modelo BERT existe un elemento clave que permite el aprendizaje bidireccional, es el mecanismo de atención. Este mecanismo consiste en que las palabras de una frase se enmascaran (se esconden) lo que obliga al modelo a analizar las palabras restantes en ambas direcciones de la frase para aumentar las posibilidades de predecir la palabra enmascarada
Un modelo BERT puede ser utilizado en casos de uso donde se requiera generar respuestas automáticas, traducción de idiomas, autocompletar textos o en nuestro caso el análisis de sentimiento para predecir el sentimiento positivo o negativo de un texto en Redes Sociales.
En Data Lab recientemente hemos incorporado una variante del modelo BERT llamado ROBERTA (Robustly Optimized BERT Approach) por supuesto utilizamos un modelo preentrenado con soporte para el idioma inglés y español, no perteneceremos al selecto grupo de empresas como Google para entrenar estos modelos, pero estamos a la vanguardia en la ciencia de datos para poder ofrecer soluciones tecnológicas que cubran las necesidades del mercado.
El análisis de sentimiento se ha vuelto clave para entender como los consumidores, usuarios o audiencias perciben los productos, servicios, eventos o marcas. No cabe duda que los algoritmos han evolucionado lo suficiente para interpretar emociones humanas en contextos difíciles ¿Crees que estos algoritmos en algún momento llegarán a dar los mismos resultados que el increíble cerebro humano puede llegar realizar con sus procesos tan complejos? ¡Déjanos tus comentarios!
¿Te interesa el análisis de sentimiento para tu negocio o proyecto? Contáctanos
¡No pierdas la oportunidad de impulsar tu marca en TikTok!
Por: Carlos Pérez, desarrollador frontend.